REST, GraphQL und gRPC Teil 4: Schnittstellenbeschreibung mit OpenAPI, IDL & GraphQL Schema
 Von: Thomas Bayer
Von: Thomas Bayer
Datum: 1. März 2021
Aktualisiert: 8. Mai 2021
Maschinenlesbare Schnittstellenbeschreibungen sind ein wertvolles Hilfsmittel beim Entwurf, der Erstellung und dem Betrieb von verteilten Systemen. Für REST, GraphQL und gRPC gibt es spezielle Beschreibungssprachen.
Eine Schnittstellenbeschreibungen hat vielfältige Einsatzgebiete:
- beim API Design
- der Dokumentation
- der automatisierten Qualitätssicherung
Darüberhinaus werden Schnittstellenbeschreibungen in der Softwareentwicklung eingesetzt. Generatoren können aus einer für Maschinen lesbaren Schnittstellenbeschreibung folgende Artifakte erzeugen:
- Client Bibliotheken
- Vorlagen für die Server-Implementierung
- Dokumentation (z.B. Swagger UI)
Dies ist der 3. Teil eines Artikels zum Vergleich von GraphQL, REST und gRPC. Die übrigen Teilen dieses Artikels behandeln die folgenden Themen:
- Teil 1: Einführung
- Teil 2: Konzepte & Architektur
- Teil 3: Formate
- Teil 5: Streaming
- Teil 6: Performanz
- Teil 7: Plattformen und Programmiersprachen
1 Beschreibung von Schnittstellen
Die Interoperabilität zwischen Client und Server kann durch das Teilen einer gemeinsamen Schnittstellenbeschreibung sicher gestellt werden. Aus derselben Beschreibung können Bibliotheken und Vorlagen für unterschiedliche Plattformen und Programmiersprachen generiert werden. Wird aus einer Beschreibung beispielsweise C++ Code für den Client und Go Code für den Server generiert, so ist sichergestellt, dass die Nachrichten von beiden Seiten verstanden werden. Die Beschreibung ist abstrakt und ermöglicht dadurch die Plattformunabhängigkeit.
Trotz der Plattformunabhängigkeit wird eine Schnittstellenbeschreibung von Client und Server geteilt und erzeugt so eine Abhängigkeit gegenüber einem dritten Modul:
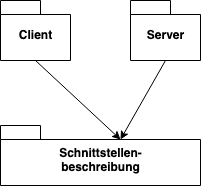
Figure 1:
Abhängigkeiten behindern in einer Microservices Architektur die Isolation der Services und deren Austauschbarkeit. Die Änderung der Schnittstelle eines Service erfordert eine entsprechende Änderung in der Schnittstellenbeschreibung und dies erfordert wiederum eine Anpassung aller Clients.
2 REST
Eine Schnittstellenbeschreibung wird für die Entwicklung mit REST nicht benötigt. Erst in letzten Jahren hat sich die Bechreibung von REST Schnittstellen etabliert.
2.1 Krieg der Beschreibungssprachen
Der Umstieg von den SOAP basierten Web Services auf REST ist in vielen Unternehmen erst erfolgt, nachdem mit OpenAPI eine vergleichbare Beschreibungssprache zu den Web Services Description Language etabliert hat. Zunächst gab es eine Fülle von konkurrierenden Beschreibungssprachen. Der Softwarearchitekt hatte die Wahl zwischen:
- RESTful API Modeling Language, RAML (Mulesoft)
- Web Application Description Language, WADL
- RESTful Service Description Language, RSDL
- API Blueprint (Apiary + Oracle)
- OpenAPI bzw. Swagger
- ...
Die Auswahl der Formate und deren geringer Marktanteil schreckte zunächst Unternehmen von einem Wechsel zu REST ab.
2.2 OpenAPI
Aus dem Krieg der Beschreibungsformate ist OpenAPI als Sieger hervorgegangen. Das Format hieß zuvor Swagger und wurde von der Firma Smartbear an die OpenAPI Initiative übergeben, einer unabhängigen Organisation der inzwischen die wichtigsten Vertreter der API-Industrie wie z.B. Google, Kong, Microsoft und Mulesoft angehören. OpenAPI ist der de facto Standard für API-Beschreibungen mit REST. Das zeigt sich u.a. auch daran, dass Mulesoft der OpenAPI Initiative beigetreten sind. Mulesoft hatte ursprünglich auf ihr eignes Format RAML gesetzt. Inzwischen unterstützen die Produkte von Mulesoft neben RAML auch OpenAPI.
Für OpenAPI Beschreibungen können YAML und JSON Dokumente verwendet werden. Das für Menschen gut lesbare YAML Format wird oft für das Erstellen und Editieren verwendet. Die Einrückungen dienen zur Strukturierung und müssen beim Editieren strikt eingehalten werden. Die Abbildung unten zeigt einen OpenAPI Ausschnitt im YAML Editor der Swaggerhub Plattform.
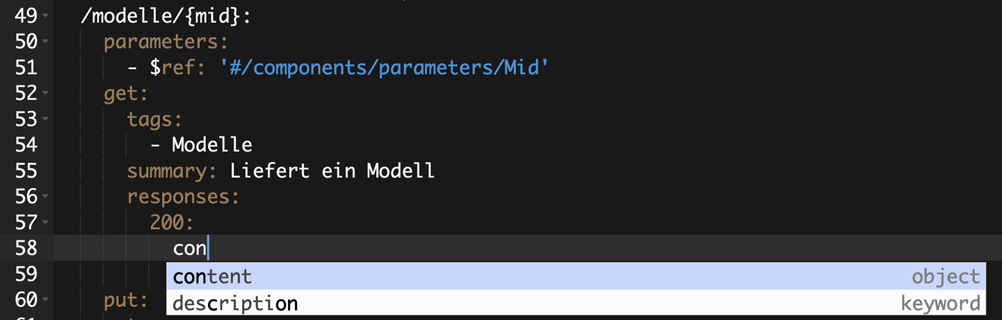
Figure 2:
Das Editieren im YAML Format ist zunächst etwas ungewohnt. Aber bereits nach wenigen Stunden ist das Editieren in YAML kein Problem mehr. Werkzeuge wie der Swagger Editor mit einer visuellen Anzeige und Autocompletion erleichtern die Einarbeitung und sorgen für Effizienz. Wer sich mit der Arbeit im Texteditor nicht anfreunden kann, kann OpenAPI Dokumente mit einem der unzähligen API Designer erstellen.
OpenAPI beschreibt die Endpunkte einer API. Ein Endpunkt ist die Kombination aus einem Pfad und einer Methode. Die Abbildung unten zeigt einen Ausschnitt aus einer API Beschreibung in der Swagger UI Oberfläche. Jeder Endpunkt ist als farbige Box dargestellt.
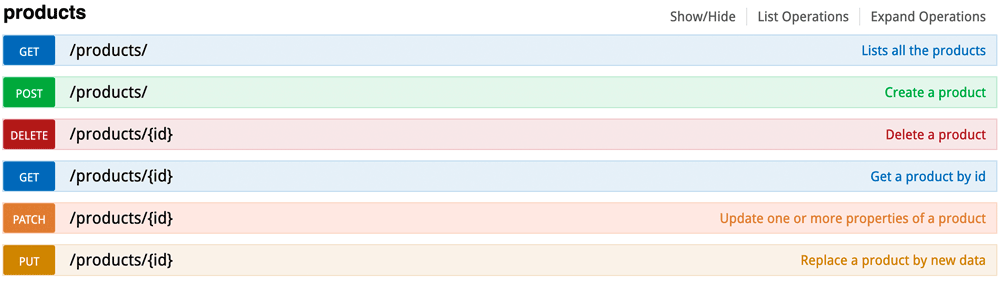
Figure 3:
Zur Beschreibung des Formats einer Nachricht können in OpenAPI beliebige Content-Types für JSON, XML, PDF, usw. verwendet werden. Eine genauere Beschreibung der Nachrichtenstruktur ist nur für das JSON-Format vorgesehen. Die JSON-Strukturen für Parameter und den Nachrichten-Body können in OpenAPI genau beschrieben werden. Für die Beschreibung wird die JSON Schema Spezifikation verwendet. Das Listing unten zeigt die Beschreibung des Datentypes Modell.
components:
schemas:
Modell:
type: object
properties:
id:
type: integer
example: 11235
minimum: 0
name:
type: string
maxLength: 20
example: Model 3
2.3 OpenAPI Werkzeuge
Zur Beliebtkeit von OpenAPI haben die Open Source Projekte von Smartbear entscheidend beigetragen, wie beispielsweise die Swagger UI oder der Swagger Editor. Das Killer-Feature der Swagger UI in der Abbildung unten ist der in der Dokumentation eingebaute API Client, mit dem aus der Dokumentation heraus ein Endpunkt aufgerufen und getestet werden kann.
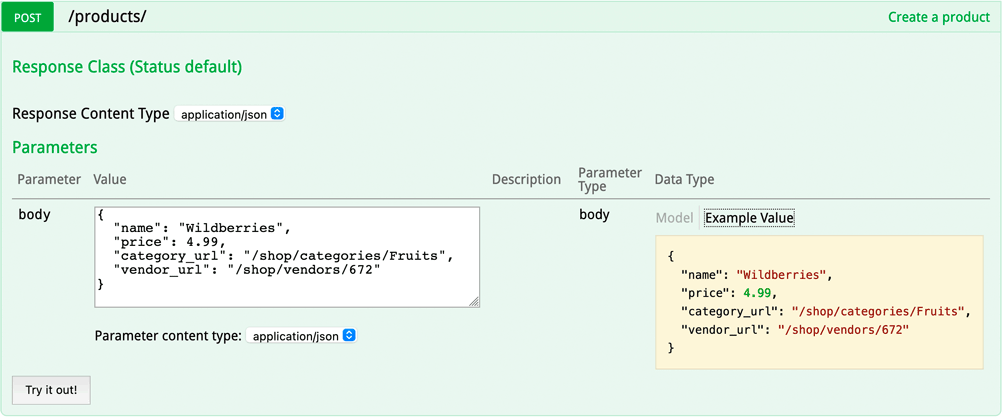
Figure 4:
Im Screenshot ist zu sehen, dass der Anwender eine fertige Datenstruktur als Parameter vorgeschlagen bekommt. Die Struktur wurde aus den im OpenAPI Dokument hinterlegten Beispielwerten generiert. Das Hinterlegen von sinnvollen Beispielen für Parameter und Datenstrukturen ist ein einfaches aber geniales Feature, das beim Testen oder Erkunden einer Schnittstelle den Anwendern viel Zeit erspart.
Neben den Tools von Smartbear gibt es inzwischen eine große Menge an Werkzeugen von den unterschiedlichsten Anbietern wie z.B. einem Swagger Plugin für Intellij von Zalando. Unter anderem stehen den Entwicklern die folgenden Werkzeuge zur Verfügung:
- Code Generatoren für Client- und Server
- Generatoren für die Erstellung von Dokumentation
- API Designer und Editoren
- Syntax Checker und Validatoren
- Visualisierungen
- Testtools und Mock-Generatoren
- Konverter von und nach OpenAPI
- Tools für die Qualitätssicherung
- Parser
Für die Entwicklungsumgebung Intellij und Microsofts Visual Studio Code gibt es mehere Dutzend Plugins für OpenAPI.
Figure 5:
2.3.1 SDK und Code Generatoren
Es gibt einige Code und SDK Generatoren für OpenAPI, von denen jeder wiederum mehrere Programmiersprachen und Frameworks unterstützt.
Einen Code Generator zu erstellen ist eine Sache, ihn zu pflegen und aktuell zu halten ist eine Herkulesaufgabe. Die Erfahrung, dass Code Generatoren viel Aufwand kosten und schnell veralten ist eine Erfahrung aus der Service orientierten Architektur, bei der die Beschreibungssprache WSDL für die Generatoren als Input verwendet wurde. Bei OpenAPI haben die Autoren ein Déjà-vu: die Generatoren unterstützen nicht die neuste OpenAPI Version, generieren Code für eine antike Framework Version beispielsweise für Java 1.7 mit Spring Boot 2.1.6 (Swaggerhub am 7.2.2021) oder der generierte Code läßt sich nicht übersetzten. Mit einem kleinen Trick läßt sich der generierte Code oft dennoch verwenden: In ein leeres Projekt mit aktuellen Einstellungen (z.B. Maven POM) werden selektiv einzelne Dateien wie Model und Controller kopiert.
2.4. OpenAPI oder Hypermedia?
Für die Erstellung von REST Servern und Clients wird keine Schnittstellenbeschreibung benötigt. Die Beschreibung einer Schnittstelle widerspricht dem zentralen REST Prinzip Hypermedia, der Verlinkung. In einer Schnittstellenbeschreibung z.B. in einem OpenAPI Dokument werden Endpunkte mit Methode und Pfad starr festgelegt. Bei Hypermedia kann eine Ressource in der Antwort über Links und Metainformationen dynamisch dem Client die möglichen nächsten Aufrufe mitteilen. OpenAPI enthält dagegen eine starre Liste, die sich nicht ändert.
Die Tatsache, dass eine Schnittstellenbeschreibung nicht benötigt wird, macht REST für Microservices interessant. Die Kopplung zwischen Client und Server wird so auf ein Minimum reduziert. Siehe hierzu auch die Einleitung zu den Schnittstellenbeschreibungen weiter oben.
Durch die Verwendung einer Schnittstellenbeschreibung gehen einer Schnittstelle die wesentlichen Merkmale von REST verloren:
- Verwendung von Ressourcen anstatt von Services
- Direkte Adressierbarkeit einer Ressource
- Sichtbarkeit der Besonderheiten des Netzwerks im Anwendungscode
- HTTP Methoden
- Status Codes
- Hypermedia
Werden aus OpenAPI generierte Client Bibliotheken verwendet, handelt es sich nicht mehr um REST sondern vielmehr um eine typische RPC Schnittstelle. Anstatt im Client über eine Methode eine Ressource anzusprechen wird eine Funktion mit einer Parameterliste aufgerufen.
Anstatt mit einem HTTP Client die folgende Abfrage abzusetzen:
findet sich im Client der Aufruf einer Funktion:
2.5 Von den HTTP Konzepten ist nichts mehr zu erkennen.
Sollte auf diese Weise eine REST Schnittstellen beschreiben werden?
Der Verlust des Hypermedia-Prinzips durch den Einsatz von OpenAPI sollte nicht überbewertet werden. Hypermedia wurde zwar als der Vorteil von REST gepriesen, aber in der Praxis wurde Hypermedia kaum verwendet.
Die Beschreibung einer Schnittstellen mit OpenAPI hat die folgenden Vorteile:
- Ansprechende Dokumentation kann mit geringem Aufwand generiert werden.
- Die Interoperabilität zwischen Client und Server wird sichergestellt
- Zahlreiche Werkzeuge stehen dem Entwickler zur Verfügung (Swagger UI, Editor, unzählige Plugins, ...)
- Der Contract-First Ansatz wird unterstützt
- Die Code-Generierung spart Zeit
3. GraphQL
Mit der Schema Definition Language, kurz SDL genannt, können GraphQL Abfragen und Datentypen beschrieben werden. Im Gegensatz zu REST ist bei GraphQL die Beschreibungssprache ein Teil der Spezifikation. Üblicherweise werden GraphQL Server mit Hilfe eines SDL Dokumentes erstellt. Es gibt für GraphQL nur die SDL und keine weiteren Alternativen.
Entwicklerwerkzeuge wie z.B. dynamische Clients können mit Hilfe eines solchen GraphQL-Schemas den Benutzer bei seiner Eingabe mit Autovervollständigung und Validierung unterstützen. Die Abbildung zeigt den Insomnia-Client der dem Benutzer einem Vorschlag für die Auswahl eines Feldnamens macht.
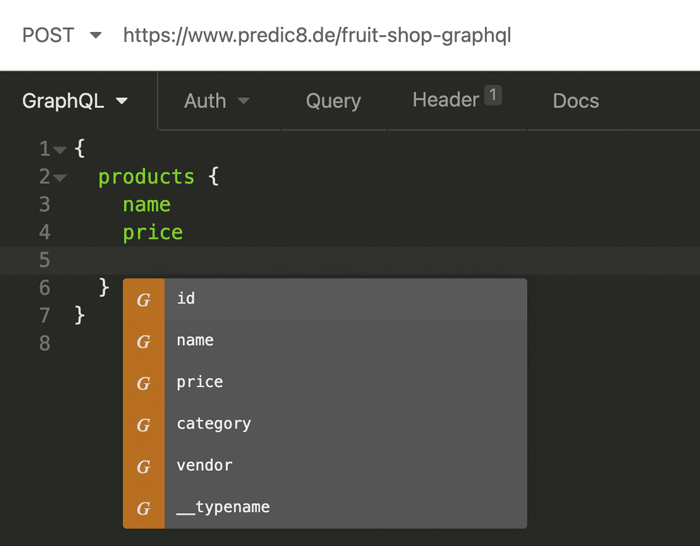
Figure 6:
Die meisten Bibliotheken für die Erstellung eines GraphQL Servers benötigen ein Schema, um Abfragen beantworten zu können.
Jedes Schema enthält die Beschreibung eines Objekttypen mit dem Namen Query. Die Felder des Query-Typen beschreiben die Objekte, die abgefragt werden können. Das Listing unten zeigt einen Query Typen welcher Abfragen von Herstellern ermöglicht.
type Query {
hersteller(id: String, name: String, ort: String): [Hersteller!]
}Optional kann ein Schema auch ein Mutation-Typ enthalten, der Funktionen zur Manipulation von Daten anbietet. Das Listing unten definiert drei Funktionen für die Manipulation von Hersteller-Objekten.
type Mutation {
addHersteller(id: Int!, name: String!, produkte: [Int]!): Hersteller!
updateHersteller(id: Int, name: String, : produkte[Int]): Hersteller!
loescheHersteller(id: Int!)
}Die im Query- und Mutation Type verwendeten Typen müssen ebenfalls im Schema vorhanden sein. Das Listing unten zeigt die Typen für Hersteller und Produkt.
type Hersteller {
id: Int!
name: String!
produkte: [Produkt]!
}
type Produkt {
id: Int!
name: String!
preis: Float!
}Über Introspection kann der Client Auskunft über die möglichen Abfragen und die definierten Datentypen bekommen. Die folgende Abfrage liefert die Namen der Datentypen eines Schema zurück. Die Abfrage des Schemas kann wie jede andere an einen GraphQL-Server geschickt werden:
{
__schema {
types {
name
}
}
}Der Server liefert als Antwort das folgende JSON Dokument zurück. Im Schema sind die fachlichen Datentypen Artikel und Hersteller definiert, sowie interne Datentypen wie String und Int. Darüber hinaus finden sich weitere Typen wie z.B. Query für Abfragen und Mutation für Funktionen zur Manipulation.
{
"data": {
"__schema": {
"types": [
{ "name": "Artikel" },
{ "name": "Hersteller" },
{ "name": "Query" },
{ "name": "String" },
{ "name": "Int" },
...
]
}
}
}3.1 Implementierung eines GraphQL Schemas
Ein Server muss für alle Felder, die im Schema beschrieben sind, eine Funktion besitzen, die Werte für dieses Feld zurückliefern kann. Diese Funktionen werden Resolver genannt. Die Resolver sind nicht Bestandteil des Schemas, sondern Teil einer Server-Implementierung.
Das Listing unten zeigt einen Resolver für das Feld artikel in der Programmiersprache Javascript.
const resolvers = {
Query: {
artikel: (obj, args, ctx, info) => R.filter(R.propEq('warengruppe',args.warengruppe ),artikel)
}
};Ein leistungsfähiges Feature von GraphQL Schema sind Directiven, mit denen die SDL erweitert werden kann. Analog zu Annotationen in Java und .NET können beliebige Stellen einer Schnittstellenbeschreibung mit Metadaten versehen werden, die das Verhalten ändern. Anwendungsbeispiele für Directiven sind:
- Überprüfung von Rechten und Richtlinien
- Formatierung von Datum oder Uhrzeit
- Validierung von Werten
- Erzeugung und Einsetzen von UUIDs
Der Entwickler kann selbst Directiven erstellen und eine Implementierung hinterlegen. Das Beispiel unten zeigt eine Direktive, die eine Monatsangabe auf einen Maximalwert von 12 begrenzt:
Dieser Artikel kann die Fülle der Möglichkeiten von GraphQL Schema nur andeuten. Über Bibliotheken und Werkzeuge können beispielsweise Schemas einzelner Microservices zu einem größeren Dokument kombiniert werden.
4. gRPC
Bei den meisten RPC Technologien wie z.B. CORBA oder Java RMI ist das Erstellen einer Schnittstellenbeschreibung der erste Schritt bei Aufbau einer remote-Schnittstelle. Bei Google RPC ist das genauso. Ausgangspunkt ist die IDL die Interface Definition Language. Die IDL für gRPC baut auf der Beschreibungssprache von protobuf auf. protobuf ist ein Framework für die Serialisierung und Deserialisierung von Objekten. Datenstrukturen werden in protobuf mit einer .proto Datei beschrieben.
Das Listing unten zeigt die Beschreibung eines ArtikelService mit einer Funktion Create.
package artikel;
service ArtikelService {
rpc Create (CreateRequest) returns (CreateReply) {}
}
message CreateRequest {
string name = 1;
float preis = 2;
Farbe farbe = 3;
}
message CreateReply {
int64 id = 1;
}
enum Farbe { ROT = 0; GELB = 1; BLAU = 2;}Die Nachrichten für die Anfrage und die Antwort werden mit protobuf-Datenstrukturen beschrieben. Die CreateRequest Nachricht enthält drei Felder, die neben dem Datentyp und dem Feldnamen eindeutige Feldnummern aufweist. Anhand der Feldnummer wird ein Feld später im Binärformat identifiziert. Da die Namen der Felder nicht in den serialisierten binären Nachrichten enthalten sind, wird zusätzlich die Größe der Nachrichten reduziert. Die Feldnummern dürfen später nicht mehr verändert werden, dafür kann aber der Name eines Feldes verändert werden, ohne dass dies Auswirkungen auf die Kompatibilität der Nachrichten hat.
Aus der IDL kann mit dem protobuf-Kompiler, dem protoc-Werkzeug, Quellcode für Client und Server erzeugt werden. Im erzeugten Code ist folgendes enthalten:
- Datenklassen für jede Nachricht
- Ein Client Bibliothek, den Stub
- Ein Server
Aus einer IDL-Datei kann Quellcode für unterschiedliche Programmiersprachen erzeugt werden. Beispielsweise ein Server in der Programmiersprache Go und ein Client für Pyhton.
Die im Service beschriebenen Funktionen müssen ausprogrammiert und vom Server bereitgestellt werden.
5. Quellen
OpenAPI
- The OpenAPI Specification @ github
GraphQL
- The Fullstack Tutorial for GraphQL
- GraphQL Rules
- Introspection in GraphQL
von Ignacio Chiazzo - GraphQL Spezifikation vom Juni 2018