SLA Metriken für Web Services
Damit die Qualität von Web Services über ein Service Level Agreement garantiert werden kann müssen geeignete Metriken zur Messung der Qualität verfügbar sein. Eine Metrik ist eine meßbare Eigenschaft eines Dienstes. Für SLA's gibt es viele Metriken, die jedoch häufig für Hardware oder Trouble Ticket Systeme ausgelegt sind. Die in diesem Artikel vorgestellten Metriken wurden auf maschinell überwachte Web Services ausgelegt und entsprechend angepasst. Daher betrachten wir zunächst wie Web Services überwacht werden können.
1. Monitoring durch Observation
Voraussetzung für die hier vorgestellten Metriken ist ein Monitoring, welche die Daten für die Berechnungen der Metriken liefert. Das benötigte Monitoring überwacht die Dienste durch periodische Test Anfragen, die Observationen genannt werden.
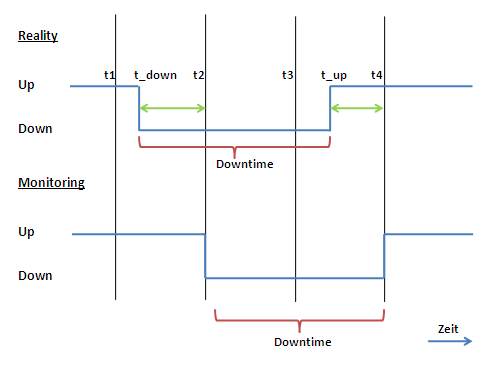
Figure 1:
Abbildung 1 zeigt den zeitlichen Ablauf eines Ausfalls. Zum Zeitpunkt t_down fällt der Service aus. Wir nennen diesen Zeitpunkt Time of Failure. Zum Zeitpunkt t_up geht der Service nach einer eventuellen Reperatur wieder in den Betrieb. Diese Zeitspanne dazwischen ist die Downtime. Ein Monitoring Tool führt in regelmäßigen Abständen Test-Aufrufe durch. Zum Zeitpunkt t1 ist der Service up. Bei der nächsten Messung zum Zeitpunkt t2 schlägt der Testaufruf fehl. Der Service wird im Monitoring auf Down gesetzt. Auch der nächste Test-Aufruf zum Zeitpunkt t3 schlägt fehl. Erst der Aufruf zum Zeitpunkt t4 veranlasst das Monitoring den Service auf Up zu setzen. Die tatsächliche Downzeit ist daher wie aus Abbbildung 1 ersichtlich etwas zeitversetzt zu der im Monitoring. Auch die Dauer stimmt nicht exakt überein. Durch entsprechend kurze Intervalle der Test Aufrufe kann die Genauigkeit des Monitoring verbessert werden. Im Folgendem werden einige Metriken beschrieben, die auf einem wie hier vorgestellten Monitoring basieren.
2. Die Metriken
2.1 Service Availability (SA)
Prozentsatz zu dem ein Service in einem Zeitraum verfügbar ist. Der Zeitraum kann die gesamte Betriebsdauer oder kürzere Abschnitte wie eine Woche oder einen Monat umfassen.
2.1.1 Datenmaterial
Die Verfügbarkeit kann über regelmäßige Tests ermittelt werden. Ein Monitoring Tool sendet dazu, wie oben bereits beschrieben, periodisch Anfragen und protokolliert erfolgreiche erfolgreiche Antworten. Es stellt sich dabei die Frage, ob es überhaupt möglich ist zur Messung Anfragen zu stellen und ob diese nicht unerwünschte Nebenwirkungen auslösen. In der Praxis findet man daher folgenden Ansätze:
- Aufruf einer unschädlichen Leseoperation
- Aufruf einer Operation mit Testdaten, die vom Service als Test erkannt werden
- Aufruf einer ungültigen Operation. Der Service muss trotzdem mit einem SOAP Envelope antworten.
- Aufruf einer speziellen Operation, die speziell für Verfügbarkeitstests angeboten wird. Diese Operationen kann auch die Einsatzbereitschaft eventuell angesprochener Backendsysteme überprüfen.
Jede dieser Methoden zum Test der Verfügbarkeit hat Vor- und Nachteile. Für die Berechnung der Verfügbarkeit macht es jedoch keinen Unterschied, welche Methode verwendet wird.
2.1.2Berechnung
Service Availabilty = Anzahl der Erfolgreichen Tests * 100 / Anzahl aller Tests
2.2 Time to Repair (TTR)
Zeit, die benötigt wird, bis ein ausgefallener Dienst wieder zur Verfügung steht. Die TTR Metrik wurde ursprünglich für Hardware Ausfälle eingesetzt.
2.2.1 Datengewinnung
Als Grundlage dienen wieder die Ergebnisse der Testmessungen. Die Reperaturzeit wird ermittelt, indem die Zeit zwischen dem ersten ausgefallenen Test und dem ersten darauffolgendem erfolgreichen Test ermittelt wird.
2.2.2 Berechnung
Time to Repair = Zeitpunkt erfolgreicher Test nach Reparatur - Zeitpunkt erfolgloser Test
2.3 Mean Time to Repair (MTTR)
Durchschnittliche Zeit, die vom Ausfall eines Dienstes bis zur Wiederbetriebnahme nach der Reperatur verstreicht. Die Mean Time to Repair wird für eine bestimmte Zeitspanne z.B. für einen Monat oder für ein Quartal ermittelt. Die Mean Down Time, kurz MDT, ist ein Synonym für die Mean Time to Repair (MTTR).
2.3.1 Berechnung
Die Time to Repair wird summiert und durch die Anzahl der Reperaturfälle geteilt.
Mean Time to Repair = Summe(TTR)/ n
2.4 Time between Failure (TBF)
Zeit zwischen der ersten erfolgreichen Observation nach Inbetriebnahme oder nach Reperatur bis zur ersten erfolglosen Observation.
2.4.1 Berechnung
TBF = Zeitpunkt Failure - Zeitpunkt Inbetriebnahme
2.5 Mean Time between Failure
Durchschnittliche Zeit, die ein Service ohne Ausfall bereitsteht.
2.5.1 Berechnung
MTBF = Summe (TBF) / n
3. Probleme
Beim Monitoring von Web Services gibt es einige Probleme, die es bei der Überwachung von anderen Systemen nicht gibt.
3.1 Monitoring von asynchronen Diensten
Synchrone Dienste, die auf eine Anfrage eine Antwort liefern sind einfach zu überwachen. Wie überwacht man aber einen Dienst, der auf Anfrage nicht antwortet?
3.2 Verfügbarkeit von Schnittstellen und Gesamtsystem
Wird beim Monitoring nur eine Testanfrage gesendet, die bei der Antwort nur nachgeprüft, ob eine SOAP Nachricht vorliegt, so bekommt man nur eine Aussage über die Verfügbarkeit der Schnittstelle. Ob die hinter der Schnittstelle vorhandene Funktionalität arbeitet erfährt man nicht.
3.3 Unterscheidung von Netzwerk/Hardware und Dienstproblemen
Bei einem Ausfall eines oder mehrerer Dienste kann die Ursache auch in einem Ausfall der Hardware oder des Netzwerks begründet sein. Eine automatische Erkennung und Berücksichtigung bei der Auswertung der Metriken ist schwierig.
4. Fazit
Service Level Agreements und Metriken für Web Anwendungen oder Call Center lassen sich nicht ohne weiteres auf Web Services übertragen.
Das Monitoring, die Datengewinnung und Berechnung der Metriken sind speziell auf die Besonderheiten von Web Services anzupassen. Nach dem Aufsetzen eines passenden Monitorings und einige Anpassungen bei der Berechnung können bekannte Metriken wie Service Availability und Mean Time to Repair eingesetzt werden.

