Videos zum Artikel
Architektur & Installation
Persistenz #2
NATS Streaming baut auf NATS Core auf und erweitert dieses um die Features:
NATS Streaming, das auch umgekehrt STAN genannt wird ermöglicht im Gegensatz zu NATS Core die garantierte Zustellung von Nachrichten.
NATS Streaming benötigt wie aus der Abbildung unten ersichtlich einen NATS Core Server für den Transport der Nachrichten. Anwendungen sprechen mit einer STAN API, die für verschiedene Programmiersprachen wie C#, Go und Java verfügbar ist. Das STAN Protokoll besteht aus ca. einem Dutzend Nachrichtentypen, die mit Googles protobuf Format definiert sind. Das STAN API übergibt die protobuf Nachrichten an die darunterliegende NATS API, die die Nachricht an einen NATS Core Server übergibt. Das Streaming Modul tritt gegenüber NATS Core als Subscriber auf, der die protobuf Nachrichten von NATS empfängt und in einem Storage ablegt. Gegenüber NATS ist das Streaming Modul nur ein Client, der sich nicht von anderen Clients unterscheidet.
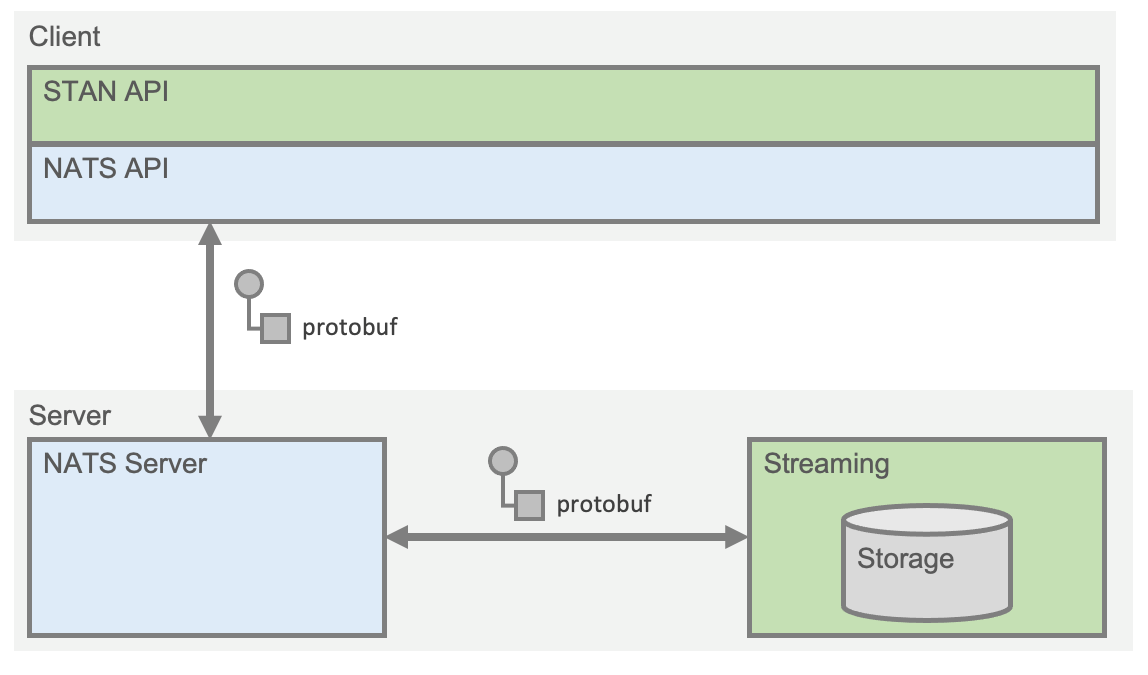
Der wesentliche Unterschied zwischen STAN und NATS ist die dauerhafte Speicherung von Nachrichten in einem Store. Mitgeliefert werden ein flüchtiger Memory Store, ein dateibasierter und ein Datenbankstore. Der Zugriff auf den Store ist über ein Interface gekapselt, so dass STAN um neue Store-Typen erweitert werden kann.
Gespeichert werden Nachrichten in einem Message Log, an dessen Ende neue Nachrichten hinzugefügt werden. Nach dem Lesen einer Nachricht durch einen Subscriber, wird diese im Gegensatz zu anderen Messaging Systemen wie z.B. dem Java Messaging Service (JMS) nicht gelöscht. Da die Nachrichten nicht gelöscht werden, können diese erneut ausgelesen werden. Beim Einrichten einer Subscription kann entschieden werden, von welcher Stelle im Log gelesen wird:
Für das Lesen von Nachrichten können verschiedene Arten einer Subscription angelegt werden.
| Subscription | Überlebt das Schließen eines Clients | Bemerkung |
|---|---|---|
| Regular | Nein | |
| Durable | Ja | |
| Queue Group | Ja/Nein | Kann zusätzlich durable (dauerhaft) sein. |
Diese Subscription überlebt das Schließen des Clients nicht. Nach dem Beenden des Clients wird die Subscription gelöscht.
Die Subscription überlebt den Konsumer. Selbst wenn kein Subscriber mehr ausgeführt wird, speichert sich der Server die Position der letzten gelesen Nachricht. Wird ein Konsumer für diese Subscription erneut gestartet erhält er die Nachrichten, die er verpasst hat, nachgeliefert. Eine Durable Subscription wird verwendet, wenn der Konsumer keine Nachricht verpassen sollte.
NATS Streaming bietet zwei alternative Ansätze für Hochverfügbarkeit und Datensicherheit: Clustering und Fault Tolerance, die in den folgenden Absätzen beschrieben werden. Beide Ansätze bieten ähnliche Eigenschaften, realisieren diese aber auf unterschiedliche Art und Weise.
NATS Streaming kann im Cluster hochverfügbar betrieben werden. Die Arbeit übernimmt ein Leader, der alle Nachrichten der Publisher entgegennimmt und diese an die Subscriber verteilt. Die übrigen Notes dienen als Backup für den Leader. Jede Nachricht wird auf die anderen Knoten repliziert, so dass beim Ausfall des Leaders keine Nachrichten verloren gehen.
Der Ablauf des Versendens einer Nachricht geht aus der Abbildung unten hervor.
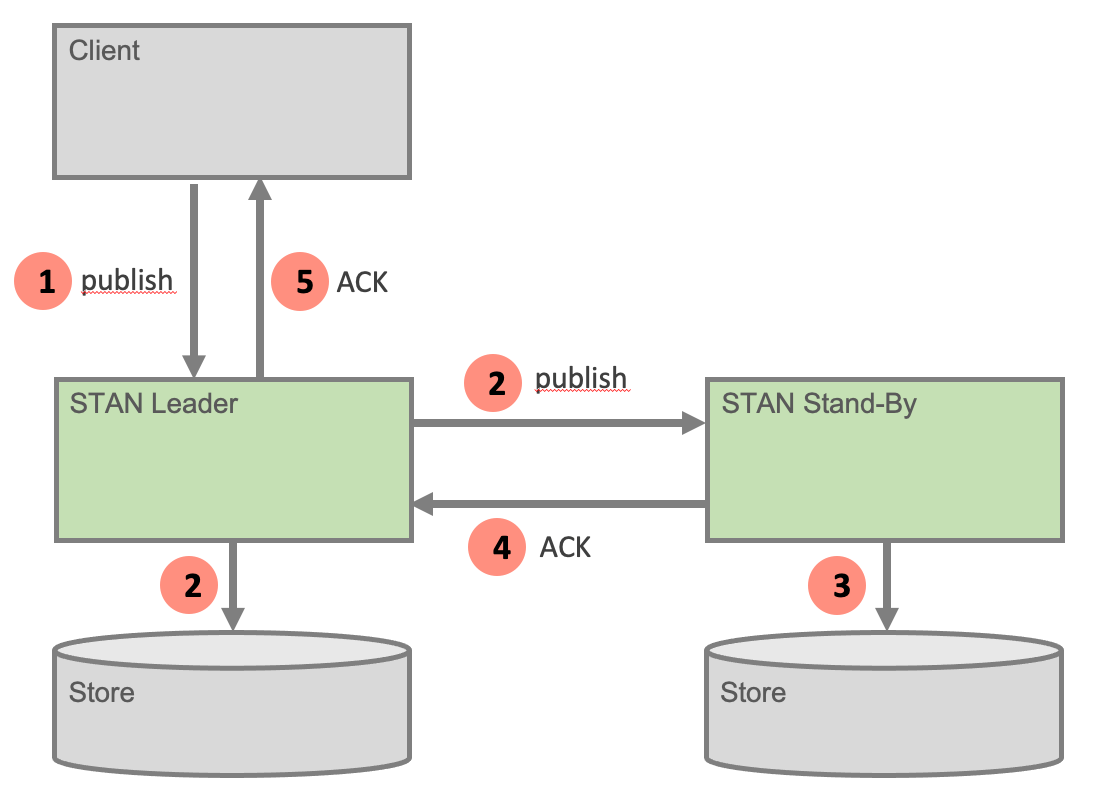
Erst wenn der Leader von allen Stand-by Knoten eine Bestätigung erhalten hat, bestätigt er dem Client den Erhalt der Nachricht. Das Warten auf die Bestätigungen führt zu Verzögerungen, so dass bei einem synchronen Versand im Client mit diesem Setup lediglich Übertragungsraten in der Größenordnung von 100 Nachrichten / Sekunde erzielt werden. Dafür wird sichergestellt, dass keine Nachricht verloren geht.
Nach dem Ausfall des Leaders wählen die übrigen Knoten einen neuen Leader aus. Ein Cluster sollte aus 3 oder 5 Knoten bestehen, um die Split Brain Problematik zu vermeiden. Mehr als 5 Knoten machen bei STAN keinen Sinn, da die Arbeit immer nur von einem Knoten als Leader verrichtet wird.
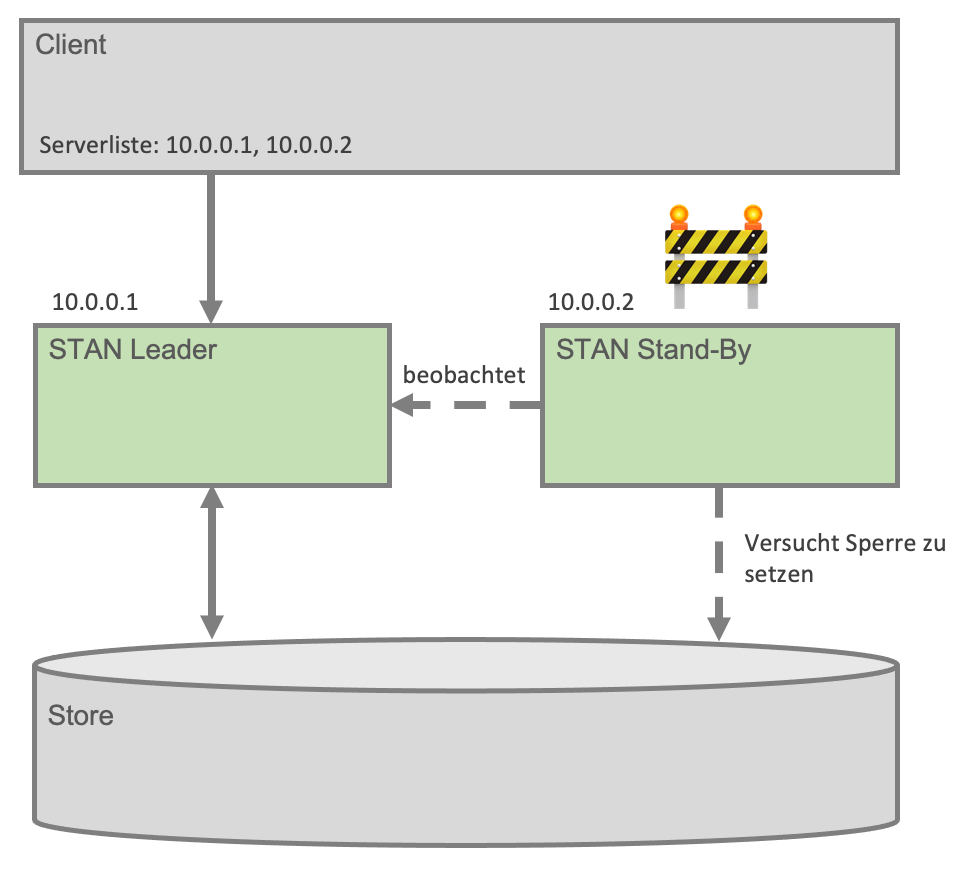
Bei Fault Tolerance teilen sich mehrere STAN Instanzen einen Datastore. Der Store, der beim Starten eine Sperre auf den Store setzen kann, wird Master. Ist es einem Knoten beim Starten nicht möglich, eine Sperre zu setzen, so fährt dieser Knoten im Stand-by Modus hoch und wartet darauf, dass der aktive Knoten ausfällt und er die Sperre setzen kann um dann selbst die Rolle des aktiven Knotens übernehmen zu können. Es können beliebig viele Server im Stand-by-Modus verharren.
Die folgende Abbildung zeigt einen aktiven Leader und einen Stand-By Knoten, der passiv darauf wartet, dass seine Stunde kommt. Nur der Leader nimmt Verbindungen von Clients entgegen und bearbeitet diese.
Die Situation nach dem Ausfall des Leaders zeigt die nächste Abbildung. Der frühere Stand-By Knoten konnte die Sperre setzen und hat daraufhin den Store auf Konsistenz geprüft. Danach wurde das Netzwerkinterface hochgefahren und Verbindungen von Clients angenommen. Im Client kann eine Liste von Knoten konfiguriert werden, die im Fehlerfall durchprobiert werden, bis ein Knoten die Verbindung annimmt.
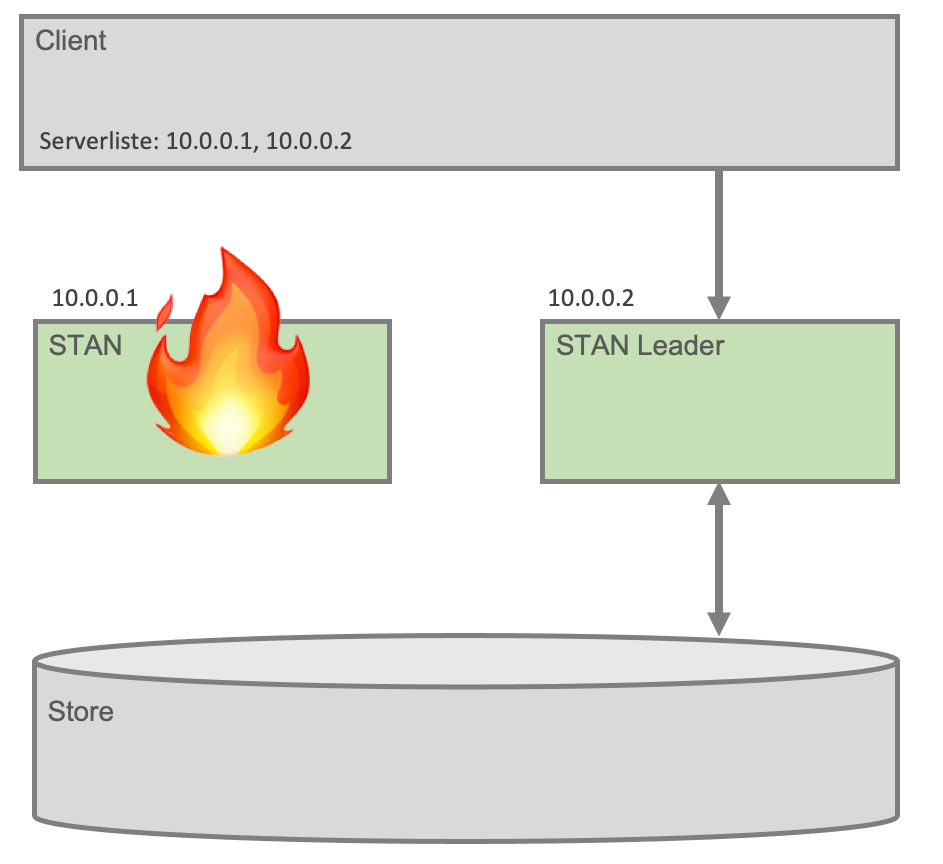
Um Ausfallsicherheit zu erzielen sollten die STAN Instanzen auf separaten Rechnern betrieben werden. Wird der dateibasierte Store verwendet, ist ein verteiltes Dateisystem nötig, welches den Zugriff von mehreren Rechnern gleichzeitig ermöglicht.
Es gibt nur einen Store und NATS Streaming kümmert sich nicht um die Verfügbarkeit der Daten im Store. Dass die Daten sicher sind, muss auf andere Weise sichergestellt werden, beispielsweise durch die Verwendung eines RAID-Arrays oder eines replizierten verteilten Dateisystems wie z.B. Ceph oder GlusterFS. Wird anstatt des Dateistores ein Database Store verwendet, muss auf der Ebene der Datenbank z.B. durch eine zweite replizierte Datenbank im Stand-by-Modus für die Sicherheit der Daten gesorgt werden.
Clustering und der Fault Tolerance Mode können dieselben Anforderungen erfüllen. Mit beiden lassen sich Hochverfügbarkeit und Schutz der Daten bei einem Ausfall realisieren. Beim Clustering übernimmt STAN die Replikation der Daten auf die beteiligten Knoten. Beim Fault Tolerance Mode sorgt sich STAN nicht um die Verteilung der Daten. Wer mit dem Fault Tolerance Mode die Daten sichern möchte, muss selbst dafür sorgen, dass die Daten sicher sind, beispielsweise durch die Verwendung eines RAID Arrays, eines verteilten Datastores oder mit einer ausfallsicheren Datenbank.
Welche Lösung die passendere ist, hängt von den Ressourcen ab, die bereit stehen. Wer bereits ein sicheres verteiltes Dateisystem betreibt, kann dieses zusammen mit dem Fault Tolerance Mode nutzen. Wer nicht über ein verteiltes Dateisystem verfügt und einfache billige Platten ohne RAID verwenden möchte, der kann Clustering einsetzen, welches sich um die Verteilung kümmert.
Die zusätzlichen Knoten in beiden Konfigurationen dienen nicht zur Verteilung der Last, sondern als Backup für den Fall eines Ausfalls. Da mit jedem Senden und Empfangen der Leader im Einsatz ist, kann mit beiden Alternativen NATS Streaming nicht skaliert werden. Es gibt keine Aufteilung der Last in Partitions oder Shards wie z.B. bei Apache Kafka oder Apache Pulsar. Was geboten wird, ist Ausfallsicherheit. Beim Ausfall des Leaders kann ein anderer Knoten einspringen.
Abhängig vom verteilten Dateisystem oder der ausfallsicheren Datenbank kann der Fault Tolerance Mode performanter arbeiten als das Clustering, da der Overhead für die Verteilung zwischen den STAN Knoten entfällt. Ob die Performanz im Fault Tolerance Mode tatsächlich besser ist oder vielleicht sogar schlechter, sollte durch einen Test geklärt werden.
STAN unterstützt eine Art von Partitioning, bei der jeder Knoten andere Channels bereitstellt. Diese Art der Partitionierung ist allerdings nicht vergleichbar mit dem Partitioning wie es z.B. Apache Kafka bietet. Mit dem Partitioning von Kafka kann der Inhalt eines Topics auf beliebig viele Knoten verteilt werden. Bei STAN können die Daten eines Topics nicht die Speicherkapazität des Knotens überschreiten.
STAN benötigt einen NATS Server oder Cluster für die Verbindung mit den Clients. STAN kann selbst einen NATS Knoten starten oder sich mit einem bestehenden verbinden.
STAN ist wie NATS mit der Programmiersprache Go realisiert und hat daher einen geringen Bedarf an Ressourcen. Der Server besteht aus einer einzigen ausführbaren Datei, die nur ca. 20 MByte groß und für Linux, Mac und Windows verfügbar ist.
Für den Betrieb im Kubernetes Cluster gibt es neben einer ausführlichen Dokumentation auch Helm Charts.
Mit Prometheus und der Dashboard-Lösung Grafana kann ein Monitoring für STAN aufgebaut werden.
Garantien für die Zustellung von Nachrichten haben ihren Preis in Form von Komplexität und Abstrichen bei der Performanz. Ein Client kann mit NATS Core Millionen von Nachrichten pro Sekunde austauschen. STAN kann die Nachrichten dauerhaft abspeichern und kommt dadurch nur noch auf wenige hunderttausend Nachrichten pro Sekunden bei einem asynchronen Versand. Wartet man beim Versand einer Nachricht auf die Bestätigung der Speicherung auf Platte durch den Broker, so sinkt die Übertragungsrate auf ca. 100 Nachrichten pro Sekunde.
Tatsächlich hängt die Performanz beim Messaging mehr davon ab, welche Garantien verwendet werden, als vom Messaging Produkt. Werden dieselben Garantien genutzt, so unterscheidet sich die Performanz bei Apache Kafka, JMS und NATS weit weniger als man vermuten möchte.
Bei NATS gibt es gegenüber Apache Kafka und Pulsar noch die Einschränkung, dass bei NATS ein Server die gesamte Arbeit übernimmt. Bei Kafka können die Nachrichten auf viele Server aufgeteilt, sprich partitioniert werden, so dass die Leistung von vielen Servern gleichzeitig erbracht werden kann. Für die Bandbreite des Clusters und die Anzahl der möglichen Clients gibt es dann keine Grenzen mehr.
Für STAN kann ebenso wie für NATS Transportverschlüsseltung mit SSL bzw. TLS, Authentifizierung und Autorisierung verwendet werden.
Nachrichten, die in einem Store zwischengespeichert werden, können für die Dauer ihrer Lagerung verschlüsselt werden. Man spricht von Secruity at "REST", da im Gegensatz zur Transportverschlüsselung z.B. mit TLS, die ruhenden Daten verschlüsselt vorliegen. Zur Verschlüsselung stehen die Cipher AES und CHACHA zur Verfügung.
Die folgende Tabelle listet die Unterschiede von NATS Streaming und NATS Core auf.
| NATS Core | NATS Streaming | |
|---|---|---|
| Lose Kopplung | Producer und Consumer müssen zur selben Zeit aktiv sein. | Producer und Consumer können zu unterschiedlichen Zeiten aktiv sein. |
| Geschwindigkeit beim Konsum der Nachrichten | Ist ein Konsumer zu langsam, droht Nachrichtenverlust. | Konsumer können mit ihrer eigenen Geschwindigkeit Nachrichten verarbeiten. |
| Garantien | At most once ➔Es ist nicht garantiert, dass eine Nachricht ankommt. ➔Es gibt keine Duplikate |
At least once ➔ Jede Nachricht kommt an ➔Es kann Duplikate geben. |
| Redelivery von Nachrichten | Nein | Ja |
| Message Persistenz | Nein | Ja |
| Durable Subscription | Nein | Ja |
| Erneutes Lesen von Nachrichten | Nein | Ja |
| Anwendungsfälle | Ständige Benachrichtigung über neue Werte (z.B. Messwerte, Aktienkurse, IoT) | Enterprise Messaging mit betriebswirtschaftlichen Nachrichten wie Bestellungen oder Zahlungen. |
| Consumer abonniert … | …ein Subject | …einen Channel |
| Wildcard Subscriptions | Subjects können in Baumform gegliedert werden. Mit > und ? kann eine Subscription auf mehrere Subjects erfolgen. | Nein |
Man sollte sich nicht verleiten lassen NATS Core abzutun und stattdessen gleich NATS Streaming einzusetzen, mit der Begründung, dass NATS Streaming mehr Features bietet. Beide Produkte haben ihre Vor- und Nachteile und sind für bestimmte Anwendungsfälle besser geeignet. NATS Core ist wartungsärmer, schneller und einfacher, dafür bietet NATS Streaming die garantierte Zustellung und die Möglichkeiten Nachrichten mehrmals zu lesen.
NATS Streaming wird langfristig von der Persistence Engine NATS JetStream abgelöst werden. Stand Oktober 2020 ist JetStream noch im Preview. Für JetStream soll es einen Migrationspfad geben, so dass man NATS Streaming heute verwenden kann und zukünftig ein Wechsel zu JetStream möglich ist.
NATS Messaging ist eine zuverlässige und leichtgewichtige Messaging Lösung, die für den Betrieb in der Cloud geschaffen wurde.
STAN erweitert NATS Core um die Garantie at-least-once bei der Zustellung von Nachrichten. Der Verlust von Nachrichten ist damit ausgeschlossen. Diese Garantie kommt mit einem Preis. Es wird mehr Speicher und mehr Rechenzeit benötigt. Die Zustellung der Nachrichten ist wird dadurch ebenfalls langsamer.
STAN eignet sich als Event Bus für Microservices und kann in der Cloud z.B. mit Kubernetes betrieben werden.
 Von: Thomas Bayer
Von: Thomas Bayer
Datum: 8. Nov. 2020
Den Code zu den Videos findest du auf github.