REST & API Versioning - The complete Reference
Over time interfaces have to be extended or modified. A modification of an interface can be backward compatible to existing clients or it can break the contract which makes also modifications of the clients necessary.
This article describes possible modifications of an REST API and discusses their impact to the compatibility to existing versions.
1. Direction
If you want to know, if a new version breaks the interface, you need to know if the new version will be deployed on the client- or server side.
Let’s take a look at two versions of an API. Version 1 supports the following paths:
/shop/products/
/shop/products/{id}Version 2 offers the additional path /shop/categories/:
/shop/products/
/shop/products/{id}
/shop/categories/Now let’s take a look at the impact of the seemingly harmless extension.
1.1 New Version at Server Side
First, we discuss the impact of a new version deployed on the server and while the clients are still using the old version 1.

Figure 1:
The old clients are using the paths from version 1 and never invoke the new path. So, everything should be fine and the interface does not break.
1.2 New Version at Client Side
Now, we are deploying the new version on some clients first and we leave the server unchanged:

Figure 2:
The version 2 clients are developed against the new API and they know the new path /shop/categories/. But what happens, when they are sending a request to that new path? They will get a response with a 404 Not Found status code. Version 1 and 2 are exactly the same as in the previous paragraph but now the interface is broken.
To decide if a modification breaks an interface, you need to know if the new version is deployed on the client or server.
Most of the time a new version of an API is first deployed on the server. However sometimes clients for a new API version are rolled out before the server gets an update. Keep that in mind, while evaluating the compatibility of a new version.
2 HTTP Protocol
REST uses the features of the HTTP protocol to express the outcome of a call or to address a resource. This section discusses the impacts of changes related to the HTTP protocol. A later chapter will discuss the modifications of the structure of the payload. For example changes to a JSON representation.
2.1 Modifications of the Paths
A resource is addressable by an URI, that is also the name of the resource.
2.1.2. Renamed Path
Let’s see what happens when a URI of a resource changes. In version 1 the resource of the supplier Western Tasty Fruits Ltd. was addressed by the following URI:
Version 2 of the API has a different URL structure and the same supplier is now reachable using the following path:
The modification of the URI structure from /shop/vendors/{id} to /shop/supplier/{id} seems to be a big change that certainly will break the interface. But does this renaming of the path really break the interface? If REST is done the way it should, the interface does not break. But in reality, things are different. First let’s take a look at the RESTful way and then at other possibilities:
a.) RESTful Clients
In conformity with REST the structure of a URI has no meaning by itself. Clients are following hyperlinks and they should not make any assumptions regarding the structure of a URI.
A RESTful client uses hypermedia to navigate from resource to resource. Suppose a client got the following representation of a product resource by a GET request. The representation has a hyperlink to the vendor of that product:
If the client wants to access the vendor of the cranberries it follows the link /shop/vendors/672. The next time the client requests a product it might get an answer from version 2. Now the link to the vendor in the representation points to /shop/suppliers/672.
A RESTful client should only have one entry point to an API and navigate from there. The structure of the URIs or respectively the paths does not belong to the contract between client and server. Therefore RESTful servers and clients are not affected by modifications of the paths.
According to Fielding APIs based on fixed resource names are not REST:
"A REST API must not define fixed resource names or hierarchies (an obvious coupling of client and server). Servers must have the freedom to control their own namespace."
b.) Not so RESTful Clients
REST is very well accepted and the value of hypermedia for APIs is well appraised. You will find a lot of APIs that include hyperlinks in the representations they serve. But only a tiny fraction of the clients make use of the hyperlinks. Let’s take a look at an example of a not so RESTful client. Assume that the client is using a REST client library that was created from an Open API aka Swagger definition. The screenshot below shows the GET method for the /vendors/{id} path in the Swagger UI. You can see the URI template /vendors/{id} and a form with the id as a parameter:
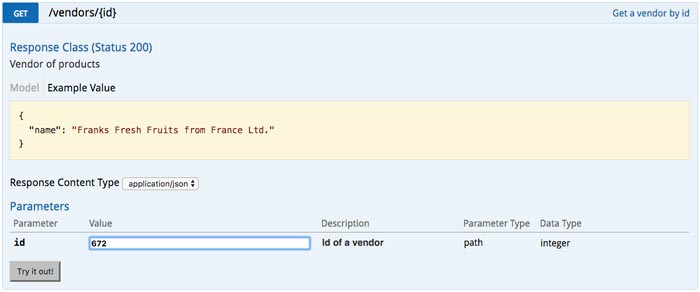
Figure 3:
Open API is expecting that the structure of the URI stays the same. And that you can build a URI by filling the template. If you generate a client library from that definition you will get a method with a signature like this:
Vendor getVendor(int id)
The getVendor method of the client library expects an integer as a parameter. But the client got the following representation with a URI pointing to the vendor:
How can the client convert the URI with the whole path into an integer? Programmers solve that by parsing the URI and just taking the number at the end of the URI. Then they pass the number to the method:
Vendor vendor = api.getVendor(672)
And the REST client lib will create a URL that is used to contact the server by filling the URI template /shop/vendors/{i}.
What happens when we change the structure of the URI with those clients? That depends on how they parse the URI. If they just take the number behind the last slash, they can get the integer from the URL. But what happens if they use a different pattern for parsing? Like:
.*/vendors/(\d*)
matched against a URI that contains /suppliers/ instead of /vendors/?
The client tries to match that with the pattern: .*/vendors/(\d.) and fails to extract the id. As a result, the interface is broken. Ok but what happens if the client can successfully parse the URI because it used a pattern like .*/(\d)$ ? The client library then will use the 672 to construct a URI:
http://api.predic8.de/shop/vendors/672
But that is the URI of the old version. If the server does not provide the old resource any more the client will receive a 404 Not Found status code. To avoid the 404 the server can answer to requests addressing /shop/vendors/{id} and /shop/suppliers/{id}. Or the server can respond to requests to the old one with an redirect to the new resource. Wether the redirect is successful depends on the HTTP client library that the REST library is using.
Best Practice: Continue to support the old URIs if you are changing the URI structure.
Hint: By using clients that are generated from Open API definitions you will loose essential properties of a RESTful interface!
The following table lists possible modifications of an APIs paths. The third column lists the impact when the new version is deployed on the server and the fourth column lists the impacts when the new version is deployed at the client.
| Modification | Description | Impact Client 1 -> Server 2 |
Impact Client 2 -> Server 1 |
|---|---|---|---|
| Additional path | New path Example:/shop/categories/ |
✔ | 404 Not Found ❌ |
| Removal of a path | 404 Not Found ❌ |
✔ | |
| Renaming of a path | Pure RESTful clients and servers will be fine. Clients will only access resources by following links they get from representations. Not so RESTful clients will break. The renaming is compareable to a removal and an addition of a path. See the rows above for the impact. |
Same as in the other direction: Client 1 -> Server 2 |
Compatible changes are marked in the table with a check mark (✔) and breaking changes are marked with a red cross (❌).
2.2 Fix for removed Paths
If you delete a path you can use a redirect to point clients to the new resource. The redirection can be setup using an API gateway or a route in the REST framework. Although the use of redirects is very common in HTTP you should check if the clients are following the redirect to the new location.
2.3 HTTP Methods
A resource can accept one or more methods. The following table lists the impact of changes to the methods a resource is accepting.
| Modification | Description | Impact |
Impact |
|---|---|---|---|
| Additional method | Example: The path /shop/products/ now accepts besides GET, POST and PUT also PATCH |
✔ | 400, 404 or 405 ❌ |
| Removal of a Method | Example: The path /shop/products/ used to accept PATCH requests but does not anymore. |
400, 404 or 405 ❌ |
✔ |
| Change of a method | Same as a removal and an addition of a method. Example:PUT instead of POST |
404 Not Found ❌ |
404 Not Found ❌ |
2.4 Parameters
Parameters can be passed to a resource in the path, the query string and as HTTP headers.
2.4.1 Path
A path parameter is part of the URI and therefore a part of the name of the resource. Path parameters are usually mandatory and cannot be made optional.
2.4.1.1 Additional or a missing Path Parameters
An additional or a missing path parameter is the same as a modification of the path. For instance, in version 1 the path looked like this:
and in version 2 we add a color parameter to the path:
That is virtually the same as a modification of a path described further above.
2.4.1.2 Typechange of a Path Parameter
The path is a string and a path parameter is therefore a string too. But the type can be further restricted e.g. by describing the interface with Open API aka Swagger.
Take a look at the following excerpt from an Open API document describing a REST resource. In version 1 the type of the parameter is string.
Version 1:Version 2 restricts the possible values to integer numbers:
Version 2:Clients sending an id e.g. a UUID that is not an integer, will cause validation errors at a server hosting version 2 of the resource.
The next table lists the impact of path parameter modifications.
| Modification | Description | Impact Client 1 -> Server 2 |
Impact Client 2 -> Server 1 |
|---|---|---|---|
| More restrictive type | The new type is more restrictive than the old one. Example:Integer instead of string |
The server may not accept the request
400, 403, 422 ❌ |
✔ |
| Less restrictive type | The new type is less restrictive than the old one. Example:string instead of integer |
✔ | The server may not accept the request
400, 403, 422 ❌ |
| Complete different type | Example: [A-Z] instead of \d{5} |
400, 403, 422 ❌ |
400, 403, 422 ❌ |
2.4.2 Query Parameters
A query parameter is appended to the URI. Query parameters are often used for optional parameters in REST APIs.
The following URI has a query string with two parameters.
/shop/products/?category=Fruits&sort=name
A query parameters is identified by a name and has a value. The order of the parameters does not matter.
Query string parameters are usually optional, so a missing parameter might not break the interface.
A query parameter that a resource does not understand is usually ignored. The reason for that is how most of the resources are implemented. The following line of Javascript code shows how a query parameter is read from a request.
If the req.params dictionary has additional entries that are not read by the implementation, the entries will be ignored.
var sort = req.params.sort;
In other languages like Java query parameters are read in a similar fashion.
| Modification | Description | Impact Client 1 -> Server 2 |
Impact Client 2 -> Server 1 |
|---|---|---|---|
| Example: Additional parameter sort /shop/products/?limit=10&sort=date |
New parameter will not be set ✔ |
Server will ignore the parameter ✔ |
|
| Removal of query parameter | Server will ignore the parameter ✔ |
New parameter will not be set ✔ |
|
| Change of order | The sequence of query parameters does not matter. ?a=1&b=2 is the same as ?b=2&a=1 | ✔ | ✔ |
| Casing of parameter name | Because query parameters are case sensitive: Same as the removal of the old parameter and the addition of a new parameter. Example:?limit=10 => ?LIMIT=10 |
See: Additional query parameter & Removal of query parameter | See: Additional query parameter & Removal of query parameter |
2.5 Header
Technical meta information can be passed from a sender to a receiver as an HTTP header parameter.
The following line shows an HTTP header location that informs the client about the location of new generated resource:
Location: https://api.predic8.de/shop/products/782
HTTP header parameters are provided to the implementation in a similar fashion to the query string parameters. The implementations just ignores HTTP headers that are unknown. According to RFC 7230 chapter 3.2.1. unrecognized header fields should be ignored.
The casing of header field names is according to RFC 7230 section 3.2. case-insensitive. The following header fields are identical. The header:
Content-Type: application/json; charset=utf-8
is the same as:
content-type: application/json; charset=utf-8
The following table lists the impact of modifications of HTTP headers.
| Modification | Description | Impact Client 1 -> Server 2 |
Impact Client 2 -> Server 1 |
|---|---|---|---|
| Additional HTTP header | Header will not be send | Header will be ignored | |
| Removal of http header | Header will be ignored | Header will not be send | |
| Change of the sequence | Sequence of HTTP headers does not matter | ✔ | ✔ |
| Change of Casing | Example: Content-Type => content-type |
✔ | ✔ |
Modification of a header value is discussed in the following sections.
2.5.1 Header Field Values
The impact of a change affecting the value of an header value depends on the specific HTTP header.
2.5.1.1 Content-Type
The Content-Type header indicates the type of the representation in the body.
It should be distinguished if only the Content-Type changes or if the format of the representation is also changed. Let’s make that clear by using an example:
The payload remains JSON but the Content-Type is changed from text/plain to application/json.
It is possible that a change of the Content-Type from XML to JSON might not break the interface in special cases. For instance, if the server is implemented using a REST framework like JAX-RS or Spring REST that maps the representation to a Java object. Before the user provided code is called the framework deserializes the XML or JSON to the very same Java object provided that both formats correspond to the structure of the Java object. In other cases, the interface will certainly break if the content of the message has a different format.
| Modification | Description | Impact |
Impact |
|---|---|---|---|
| Modification of the major media type | Example: text/xml into application/json |
❌ | ❌ |
| Modification of the minor media type | Examples: image/png to image/gif |
||
| Encoding | Example: Iso-8859-1 to utf-8 |
✔1 | ✔1 |
1) If a framework or server takes care of a different encoding, it doesn't matter. However, if a client or server is reading the representation as octet stream there might be problems with special characters like the German “Umlaute”.
2.5.1.2 Accept Header
Client and server can negotiate what content they prefer and understand. A client can send an Accept HTTP header in its request to the server, indicating what content types it accepts and prefers.
In REST APIs, a use-case of the Accept header is to indicate if the client wants an XML or JSON media type as response.
The following table lists only the impact for new client versions because only clients are sending Accept headers.
| Modification | Description | Impact Client 2 -> Server 1 |
|---|---|---|
| Change of the media type | Example: |
The client will not understand the payload of the servers response ❌ |
| Removal of the header | The client does not send the header anymore. | The server sends the default media type. If the default type is different from want the client expects the change will break. ❓ |
| New header | The client now sends an Accept header with its requests | If the server understands the header and is able to deliver it will send a response with the desired media type. It is also possible that the implementation or the REST framework do not care about the HTTP header. ❓ |
What if the client sends an Accept header asking for XML and the server does only support JSON? Let’s have a look at an example session. The client indicates that he wants XML:
curl https://api.predic8.de/shop/products/ -H "Accept: text/xml" -v > GET /shop/products/ HTTP/1.1 > Host: api.predic8.de > User-Agent: curl/7.54.0 > Accept: text/xml
The server ignores the wish of the client, answers with JSON and informs the client about the media type with the Content-Type header.
< HTTP/1.1 200 OK < Content-Type: application/json; charset=utf-8
Because the client expects in this example XML there is a very high probability that the client will not understand the JSON message from the server and will throw an error.
2.5.1.3 Location Header
The location HTTP header informs the client about the URI of a newly created resource or a redirected location.
Let’s see what happens when the value of the location header changes in the following example. Suppose a client wants to create a new resource by sending the following request:
POST /shop/products/ HTTP/1.1
Host: api.predic8.de
Content-Type: application/json
{
“name”: “Pears”
}Version 1 of the server would answer with the following response:
HTTP/1.1 201 Created Cache-Control: no-cache Content-Type: application/json Location: https://api.predic8.de/shop/products/98
A response with status code 201 Created indicates to the client that his request has created a new resource. But how to address the newly created resource? To inform the client about the URI of the new resource the server is providing a Location header in the response:
Location: https://api.predic8.de/shop/products/98
Now the client knows where he can access the newly created resource.
In version 2 the service is sending back a URI with a different path structure. Instead of:
../products/…
the new version is sending back:
…/articles/…
as you can see in the listing below:
HTTP/1.1 201 Created Cache-Control: no-cache Content-Type: application/json Location: https://api.predic8.de/shop/articles/98
Does that modification break the interface? If REST is done the way it should, the interface does not break. But in reality, things are different. First let’s take a look at the RESTful way and then at other possibilities:
a.) RESTful Clients
In REST the structure of an URI has no meaning by itself. Clients are following hyperlinks and they do not make any assumptions regarding the structure of URI. So, a RESTful client will read the location header and can use the URI to retrieve the newly created resource. REST keeps you save and you do not have to worry about interoperability.
b.) Not so RESTful Clients
REST is very well accepted and the value of hypermedia for APIs is well appraised. You will find a lot of APIs that include hyperlinks in the representations they serve. But only a tiny fraction of the clients make use of the hyperlinks. Let’s have a look at an example of such an client. Assume that the client is using a REST client library that was created from an Open API aka Swagger definition. In the screenshot below you can see the URI template /products/{id} and a form with the id parameter:
Figure 4:
Open API is expecting that the structure of the URI stays the same. And that you can build an URI by filling out the template. If you generate a client library from that definition you will get a method with a signature like this:
Product getShopProductId(int id)
The response to a POST request contains a URI like the following in the location header:
http://api.predic8.de/shop/products/67
But to get the product you have to supply an integer? How to get an integer from the URI? Programmers solve this by parsing the URI and just taking the number at the end of the URI. Then passing the number to the method:
Product getShopProductId(67)
And the REST client lib will create a URL that is used to contact the server.
I have seen many clients that are built as described above in the last years. What happens, if we change the structure of the URI with those clients? That depends on how they parse the URI. If they take the number behind the last slash then the interface will not break. But what happens if they use a different pattern for parsing? Like:
.*/products/(\d*)
Version 2 of the server now returns the following URI:
http://api.predic8.de/shop/articles/67
The client tries to match that with the pattern: .*/products/(\d.) and fails to extract the id. As a result, the interface is broken. Ok but what happens if the client can successfully parse the URI because it used a pattern like .*/(\d)$ ? The client library then will use the 67 to construct an URI:
http://api.predic8.de/shop/products/67
But that is the URI of the old version. If the server does not provide the old resource any more the client will receive a 404 Not Found status code. To avoid the 404 the server can answer to requests addressing /shop/articles/{id} and /shop/products/{id}. Or the server can respond to requests to the old one with an redirect to the new resource. If the redirect is successful depends on the HTTP client library that the REST library is using.
Best Practice: Continue to support the old URIs if you are changing the URI structure.
Hint: By using clients that are generated from Open API definitions you will loose essential properties of a RESTful interface!
c.) Ignorant Client
In the most likely case the client just ignores the Location header and uses only URI templates or hardcoded URI construction like:
Sting uri = “https://api.predic8.de/shop/products/” + id;
Then again, the clients will make requests to the old location of the resources instead of sending requests to their new destination.
| Modification | Description | Impact Client 1 -> Server 2 |
|---|---|---|
| New header | The server now responds with an additional Location header. | The client will use it or ignore it. ✔ |
| Removed header | The server does not send the Location header any more. | The client can try to access the location header and produce an error. Or the client was not reading the field and just ignores it.
Likely to break ❌ |
| Modified URI structure | Example: /shop/products/7 => /shop/articles/7 | Pure REST full client will use the new URI and be fine. Not so RESTful clients might break. |
2.5.1.3.1 Other HTTP Headers
There are many more HTTP headers. The majority of those headers do not have any impact on version compatibility. Please let me know, if you experience any problems with other headers, so I can update this article.
2.6 Status Codes
HTTP status codes inform the client about the outcome of a call.
A prototypical modification is the introduction of more specific codes. Assume the first version of a REST resource returned for all successful invocations the status code 200 Ok. In the next version, the service is responding with a 201 Created if a new resource was created e.g. by using the POST method on a container resource like /products/.
Suppose the client uses the code below to test for the outcome of a call. The code 201 is within the range between 200 and 299 so there will be no impact on that client.
Now let’s assume, we have a poorly implemented client that tests for success with the following code:
Now things are different. 201 is obviously not equal to 200 and therefore the client considers the call failed.
Proper implemented REST clients should be able to deal with different status codes without modification. The table below lists status codes that are common in REST and are usually handled well by the clients. Most of the status codes are not returned by the code of the service implementation. The codes 401, 403 and 407 are usually returned by the security framework or the web server. They can change by a modification of the security configuration, an update of the HTTP or application server software. Usually 502 Bad Gateway is returned by an API gateway instead of the service. So you can get different status codes even if the version of your REST API stays the same. For example the update of your web server or API proxy can cause the return of different status codes.
| Code | Description | Returned by Infrastructure |
|---|---|---|
| 200 | ✔ | |
| 201 | Created | |
| 202 | Accepted | |
| 400 | Bad Request | |
| 401 | Unauthorized | X |
| 403 | Forbidden | X |
| 404 | Not Found | X |
| 405 | Method not Allowed | X |
| 406 | Not Acceptable | X |
| 407 | Proxy Authentication Required | X |
| 408 | Request Timeout | X |
| 415 | Unsupported Media Type | X |
| 429 | Too Many Requests | X |
| 500 | Internal Server Error | X1 |
| 502 | Bad Gateway | X |
| 503 | Service Unavailable | X |
| 504 | Gateway Timeout | X |
3 Conclusion
REST is a good approach for APIs with a long lifecycle. It is possible to heavily extend a REST API without breaking backward compatibility provided that the server and the clients are really adhering to the REST principals. The majority of the usual "REST" clients will be more brittle in regard to versioning, but still more resilient than most of the RPC style APIs.
4 Resources
4.1 Articles and Blog Posts
- REST APIs must be hypertext-driven, Roy T. Fielding
- Versioning a REST API, Eugen Paraschiv
4.2 Specifications
- RFC 7230, Hypertext Transfer Protocol (HTTP/1.1): Message Syntax and Routing
- RFC 7231, Hypertext Transfer Protocol (HTTP/1.1): Semantics and Content
- RFC3986: Uniform Resource Identifier (URI): Generic Syntax, https://www.ietf.org/rfc/rfc3986.txt
 Von: Thomas Bayer
Von: Thomas Bayer
Datum: 15. Nov. 2017
Aktualisiert: 2. Feb. 2019